#카카오톡 링크 인식 분석[실험]
[ 발견 ] 편에 이어서 카카오톡이 어떤 텍스트를 링크로 인식하는지 확인하기 위하여 테스트용 텍스트를 여러개 만들어 실험하였다.




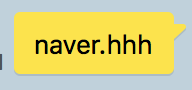






여기까지의 실험으로 다음과 같은 결론을 내릴 수 있다.
1) 1, 2, 3, 4 번으로 보아 프로토콜(http(s)) 가 있던 없던 링크로 인식한다.
2) 4번, 5번으로 보아, 마지막에 올 수 있는 도메인이 명확하게 있다.
3) 6번, 7번으로 보아, 링크 앞에 딸린 특수문자는 제외하고 링크로 인식
4) 9번으로 보아, 도메인 마지막의 특수문자는 제외하고 링크로 인식
5) 10,번, 11번으로 보아 - 한개는 링크로 인식, --는 링크로 인식하지 않는다.
8번으로 보아 URL 에서 사용되는 특수문자 / _ - & = ? 같은 경우 좀더 실험 할 필요가 있어보인다.
아래 에는 도메인 뒤에 나올 수 있는 특수문자를 테스트 해보았고, 다음 3가지의 경우로 나눠 볼 수 있다.
1. ~!@#$%^&*()_+-=;:’”,.?<>` 의 특수 문자가 올 경우 특수문자를 무시하고 앞에 부분만 링크로 인식




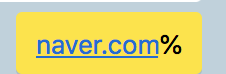















2. _가 올경우 텍스트로 인식.

3. /가 올경우 /를 포함하여 링크로 인식


뒤에 나올 수 있는 도메인 규칙까지 포함하여 정리하면 다음과 같다.
1) 1, 2, 3, 4 번으로 보아 프로토콜(http(s)) 가 있던 없던 링크로 인식한다.
2) 4번, 5번으로 보아, 마지막에 올 수 있는 도메인이 명확하게 있다.
3) 6번, 7번으로 보아, 링크 앞에 딸린 특수문자는 제외하고 링크로 인식
4) 9번으로 보아, 도메인 마지막의 특수문자는 제외하고 링크로 인식
5) 10,번, 11번으로 보아 - 한개는 링크로 인식, --는 링크로 인식하지 않는다.
6) 12번으로 보아 (문자열.) 조합이 1 개 이상, 최대 4개 까지 올 수 있음.
7) ₩~!@#$%^&*()+-=;':",.<>? 의 특수문자가 나오는경우 앞에 특수문자 전까지만 링크로 인식
8) _가 나올경우는 전체를 문자로 인식
9) /가 나오는경우 /뒤 전체를 포함하여 링크로 인식.
다음 장에서는 위 규칙을 바탕으로 코드로 옮겨보도록 하겠다.